
Personal data collection and analysis
Motivation behind this example
I was diagnosed with sleep apnea last year, and have to use a continuous positive airway pressure (CPAP) machine to sleep well enough to feel alert during the day. The machine uploads data (via cellular connection) to a website that will give me results for the last two weeks. This data includes both usage (time of usage, air leakage, number of times mask was put on/taken off), and results (apnea-hypopnea index, which is an average of the number of times per hour that slow or no breathing occurred for at least 10 seconds). The website only displays results from the last two weeks, and I’d like to eventually do a long-term analysis. I’d also like to have things displayed my own way, because, well, I’m like that.
I could enter this information in a spreadsheet, and for import into R or other statistical software that might be the sensible thing to do. However, by having this data in context of other diary entries and text surround it I get to see this data in context of other things going on in my life. This information does not exist in a vacuum, and is important context for other things. For instance, if I’m dealing with a particularly stressful situation, it would be nice to go back and see how I dealt with that in the context of how my sleeping is going (and vice versa - does the apnea get better or worse during that time?). Another issue is that I’m dealing with migraines, and I’d like to know something about the frequency and severity in the context of sleep.
Methodology for data collection
This personal data collection exercise uses an excellent piece of software specifically for journaling called The Journal. I’ve been using The Journal since 2007 to record events and just simply jog my memory of goings on in my life. The software has a few nifty features that dovetail nicely with data collection.
Daily entries
The Journal splits writing up into categories. Categories can be either loose-leaf (where entries can be organized hierarchically any way you want) and daily (where entries are organized by the date of entry). If you set it up a certain way, you can have the Journal lock entries on every day except for the day you are working on. It can also automatically create an entry for the day you are working on. Very handy for just daily jouraling in general.
Topics
Topics are tags for specific pieces of text or entries. If you select a piece of text and tag it with a topic (say, CPAP), you can extract that piece of text later. Couple this with the Search by Topic command, and you can extract all text tagged with a certain topic into one document and save a single document with all text from that topic. So, for example, I will tag all my CPAP writings with the CPAP topic, and later on save a text file with what I have written about CPAP therapy (in this case, the data I collected).
Templates
The Journal has a sophisticated template system that can insert not only the same text over and over, but tag it automatically with a certain topic and even fill in certain data such as the current date and time. I use the template feature to create some structured text (a data entry form of sorts) and tag the whole piece of inserted text with the CPAP topic. That way, I don’t have to bother with selecting and tagging manually. I can simply insert the text and fill in the numbers when I read the website.
The template looks like this:
Sleep numbers for <ENTRYDATE format=“mm/dd/yyyy”/>
* Usage:
* Leakage: L/min
* AHI: events/h
* Mask on/off:
* MyAir score:
* Comments:
Because the text follows the same structure for all such entries, it is easy to write R code to pull out the data and make a data.frame.
What you don’t see (and is hard to show here) is that in the template itself I selected all of the text and tagged it CPAP. That way, my CPAP entries will always be tagged, and I can easily extract them later.
Methodology for analysis
Data extraction
The first part of data extraction is in The Journal. I use a saved search from the Search Entries by Topic function, then click View All Result Entries to see the text I had entered. The result is a screen showing the last 100 pieces of text I tagged CPAP (which may include other pieces of text if I felt the need to write on the topic). I can change this with an option. Clicking Save to File will allow me to save to a Journal file, and RTF, or a TXT file. I save the result to a TXT file so that I can easily read it in R. The text file contains only the data I entered for the CPAP machine, as well as any other text I tagged (which is fairly uncommon).
Data import
This is where I pay the price for putting the data in a diary rather than a tabular format. I use readlines.
library(readr)
library(dplyr)
library(stringr)
library(ggplot2)
raw_file <- "_Rmd/cpap.txt"
if (file.exists(raw_file)) {
# file.copy(raw_file,backup_file,copy.date = TRUE)
raw_lines <- read_lines(raw_file)
data_row <- 0
cpap_df <- data.frame(date=c(),usage=c(),leakage=c(),events=c(),mask=c(),score=c())
for (this_line in raw_lines) {
if (str_sub(this_line,1,18) == "Sleep numbers for ") {
data_row <- data_row+1
cpap_df[data_row,"date"] <- as.Date(str_sub(this_line,19),"%m/%d/%Y")
} else if (str_sub(this_line,1,9)=="* Usage: ") {
tm <- str_extract(this_line,"1?[0-9]{1}:[0-9]{2}")
tm <- as.numeric(str_split(tm,":")[[1]]) %>%
(function(x) x[1]*60+x[2])
cpap_df[data_row,"usage"] <- tm
} else if (str_sub(this_line,1,11)=="* Leakage: ") {
cpap_df[data_row,"leakage"] <- as.numeric(str_extract(this_line,"[0-9]+"))
} else if (str_sub(this_line,1,15)=="* Mask on/off: ") {
cpap_df[data_row,"mask"] <- as.numeric(str_extract(this_line,"[0-9]+"))
} else if (str_sub(this_line,1,15)=="* MyAir score: ") {
cpap_df[data_row,"score"] <- as.numeric(str_extract(this_line,"[0-9]+"))
} else if (str_sub(this_line,1,7)=="* AHI: ") {
cpap_df[data_row,"events"] <- as.numeric(str_extract(this_line,"[0-9\\.]+"))
}
}
for (data_row in 1:nrow(cpap_df)) {
if (all(is.na(cpap_df[data_row,]))) {
cpap_df <- cpap_df[1:(data_row-1),]
data_row <- data_row-1
}
}
# write_csv(cpap_df,csv_file)
} else {
cat("Oops! ",raw_file," does not exist!\n")
}The commented out code above basically writes out the file to a CSV (for easier processing in the future if I need) and backs up the CSV file each time I run the analysis. (I run this analysis in an R Studio R notebook.)
This code is basically a brute force conversion of the structured text of the template into a data frame - the text indicates the variable (column), and the row is given by a counter that is incremented every time a new entry, as indicated by the text “Sleep numbers for”, is read. The decisions on the variables are made in a rather old-fashioned way, with long if … else if … else block. The str_sub commands from the stringr package (you could also use base, if you wish) look for the substrings that I know will be present due to the template function in The Journal (and the hope that I don’t overwrite them when I record data), and the str_extract function will look for the numerical digits for most lines, two numbers separated by a colon (i.e. a time) for the usage line, and digits or a decimal point for the AHI line. These are converted to appropriate dates and numeric values, with the exception of the usage, which is converted to minutes.
The code above is slightly flawed in that there is the possibility for records that are all missing, so the last for block steps through and eliminates those records.
This is the most complicated part of the analysis! Once this data is in a data.frame, you can treat it as any other data analysis.
Data analysis
I won’t focus too heavily on the data analysis here, but just to demonstrate here is a usage graph:
cpap_df %>% ggplot(aes(as.Date(date,origin="1970-1-1"),usage)) +
geom_hline(aes(yintercept=480),color="red",lty=2) +
geom_line() +
xlab("Date") +
ylab("Usage (minutes)") +
scale_y_continuous(limits=c(0,NA)) +
scale_x_date(date_labels = "%b %d")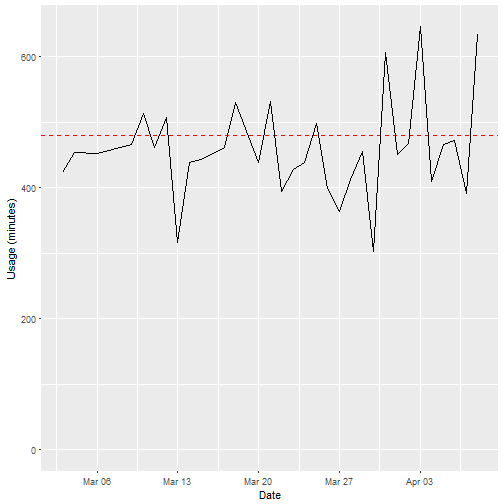
No, you don’t get to see the other stuff, how much I sleep is enough!
Discussion
While it might be easier in some ways to enter this data into a spreadsheet daily, I chose this method of personal data collection for several reasons:
- It allows me to put each day’s data into context, for example recording in prose whether that day was stressful, was a holiday, or had work pressures
- It enables me to enter several kinds of data into a diary (e.g. migraine data, dietary data, exercise data), and use multiple extractions to correlate data
Because I use The Journal almost daily, and because it has these sophisticated features, I use that as a central location for all sorts of personal data, and so it became the natural place to record my sleep habits, and it is also a good piece of software to use to record other habits. Perhaps it can also supplement Fitbits, Garmins, and other kinds of personal habit data collection workflows.